Cooperation for mutual benefit is a fundamental aspect of politics and human behavior. Game theoretic models and empirical behavioral-economics research can both provide knowledge about the degree to which humans tend to cooperate and the conditions under which they do so. However, results from these two types of inquiry can sometimes seem inconsistent with each other. Game theory tells us that from a traditional economic (rational egoist) perspective it is often not optimal to cooperate when in a one-time (or non-repeated) interaction with another individual. However, experimental research with real humans has shown that many individuals are generous and cooperative even in one-time interactions.
In the famous "Prisoner's Dilemma" game, for example, both players will get a good outcome if both players cooperate to help each other. Each player would hope that the other player will cooperate, but the incentives of the game are defined such that each player individually gets a better outcome by choosing not to cooperate, regardless of whether the other player cooperates.

However, actual human behavior seems to be a little different. In lab experiments in which real human subjects are given opportunities to play the Prisoner's Dilemma game for real money, many subjects choose to cooperate even when they are told that it is a one-time interaction and the game will not be repeated. This seems to be irrational behavior because the subjects would earn more money by choosing not to cooperate. This observed behavior needs an explanation.
One possible explanation is the artificiality of certainty about the situation. The typical experimental situation in which subjects are told with certainty that they are in a one-time interaction is unlike the situations humans often encounter in real life. In real interactions, an individual would have a belief about whether the current interaction will be a one-time interaction or a repeated interaction, but those beliefs could sometimes be incorrect. The opportunity cost of failing to cooperate when an interaction that was believed to be a one-time interaction turns out to be a repeated interaction may be greater than the cost of cooperating when an interaction turns out to be a one-time interaction. A tendency to cooperate even when the individual believes the interaction is most likely a one-time interaction could thus be beneficial in the long run.
Delton et al. model
Delton, Krasnow, Cosmides, and Tooby (2011) created a computer-simulation model to show how the tendency to cooperate even in one-time interactions, as a heritable behavioral trait, could evolve by natural selection over thousands of generations. This model involves a population of hundreds of simulated individuals making decisions. Each of these simulated agents in the population is randomly paired with another of the agents to participate in a Prisoner's Dilemma game. Some of these pairings are assigned to be a one-time interaction, while other pairs are assigned to have repeated iterations of the game. If the pair is assigned to a repeated interaction, the two agents play a randomly determined number of rounds of the Prisoner's Dilemma game together. On each round of the game, there is some probability that the pair will play another round together.
The agents never know whether their current interaction will be repeated, but they do receive clues. Each agent receives a cue value drawn from a random normal distribution. The mean of the distribution of possible cue values differs depending on whether the agent is in a repeated interaction or a non-repeated interaction. However, there is some overlap between the two distributions of possible cue values such that the cue value the agent receives cannot provide complete certainty about which distribution it was drawn from. For example, in the illustration below, if an agent receives a cue value of -2, the agent might feel almost certain that the current interaction is a non-repeated interaction (assuming there wasn't an extremely high base-rate probability of repeated interactions). However, if the agent receives a cue value of 0, the agent could reason that, although a non-repeated interaction would have been more likely to produce such a cue value, a repeated interaction could also plausibly have done so.

Thus, though the agent does have some clue, the agent does not have perfect information about whether the interaction is to be a one-time interaction or a repeated interaction. With their knowledge of the cue value they received, their knowledge of the two distributions of possible cue values, and their knowledge of the base-rate probability of an interaction being repeated, each agent then uses Bayes' formula to calculate the updated probability that their current interaction will be repeated. If the probability is greater than 1/2, the agent is said to believe that the interaction will be repeated.
Each simulated agent possesses two inherited trait values that determine the agent's decision strategy in the Prisoner's Dilemma game. The agent has one trait value that specifies the probability that the agent will cooperate if the agent believes the interaction is more likely to be a repeated interaction and another inherited trait that specifies the probability of cooperating when the agent believes the interaction will not be repeated. In the first generation of the simulation, all agents start with a value near 1 for the former trait and value near 0 for the latter, with a small amount of random variation in the trait values across the population.
Based on their inherited trait values, each agent thus makes a decision about whether to cooperate in the current interaction. An agent who decides to cooperate plays a "tit-for-tat" strategy, while an agent who decides not to cooperate plays an "always defect" strategy.
The model simulates thousands of generations. In each generation, there is a population of hundreds of agents. Each agent is randomly paired with one other agent. If they are assigned to a one-time interaction, the two agents play one Prisoner's Dilemma game before they die. If they are assigned to a repeated interaction, they play a stochastically determined number of Prisoner's Dilemma games before they die. At the end of each generation, the population of agents dies and is replaced by a new population of agents. The new agents are offspring of the previous generation of agents, but not in a one-to-one relationship. At the end of each generation, each agent reproduces in proportion to their total earnings in the Prisoner's Dilemma games played in their lifetime. More specifically, each agent in the new generation has one parent, chosen at random, from the previous generation. For each agent in the new generation, the probability that the agent's parent will be any given agent of the previous generation is equal to that previous-generation agent's proportion of the total earnings of all the previous generation's agents.
Each agent inherits the trait values of its parent. However, the inherited trait value may, with some probability, mutate when passed from parent to offspring. A mutation is some value, drawn from a random normal distribution centered on zero, added to the previous trait value. If the new trait value would fall below zero, the new trait value is said to be equal to zero. If the new value would be above 1, the new value is 1. This ensures that the probabilities will always be between 0 and 1.
Thus, over thousands of generations of simulated agents interacting with each other, producing offspring in proportion to their level of success in those interactions, and passing their behavioral tendencies to their offspring with small random changes, the inherited tendency to cooperate or not cooperate can evolve through the processes of mutation and natural selection. Delton et al showed that, depending on the parameters chosen for the model (e.g. the base-rate probability of an interaction being repeated, the distance between the two distributions of possible cue values, or the benefit of the other player's cooperation in ratio to the cost of one's own cooperation), natural selection will often produce a population in which it is common for agents to choose to cooperate even when they believe the current interaction is not likely to be repeated.
My revised model
A possible criticism of the Delton et al. model is that it gives too much of an unfair advantage to agents who are assigned to repeated interactions. Agents who are assigned to a one-time interaction get to play only one iteration of the Prisoner's Dilemma game in their lifetime before they die, while agents who are assigned to a repeated interaction get to play several games in their lifetime. This is similar to saying that agents who get assigned to repeated interactions get to live longer. This unfairly disadvantages the strategy of defecting. In the Delton et al. model, an agent who chooses to defect knows they will never get any future opportunities to earn anything in their lifetime. However, in a different model, an agent who chooses to defect could know that, although they won't get additional opportunities to earn anything from future interactions with their current partner, they may still get future opportunities to defect against other partners who might naively cooperate with them. In a different model, a non-cooperating agent could go on to interact with many different agents in their lifetime, potentially earning additional rewards.
I created a revised version of the model to fix this problem. In the revised model, all agents within a generation play the same number of Prisoner's Dilemma games. In each round, there is some probability that another round will occur. If another round does occur, each agent is randomly assigned to play the next round either with their current partner or with a new partner. Thus, unlike the Delton et al. model, in which each agent interacts with only one other agent in their lifetime, the revised model allows each agent to interact with many different agents during a lifetime.
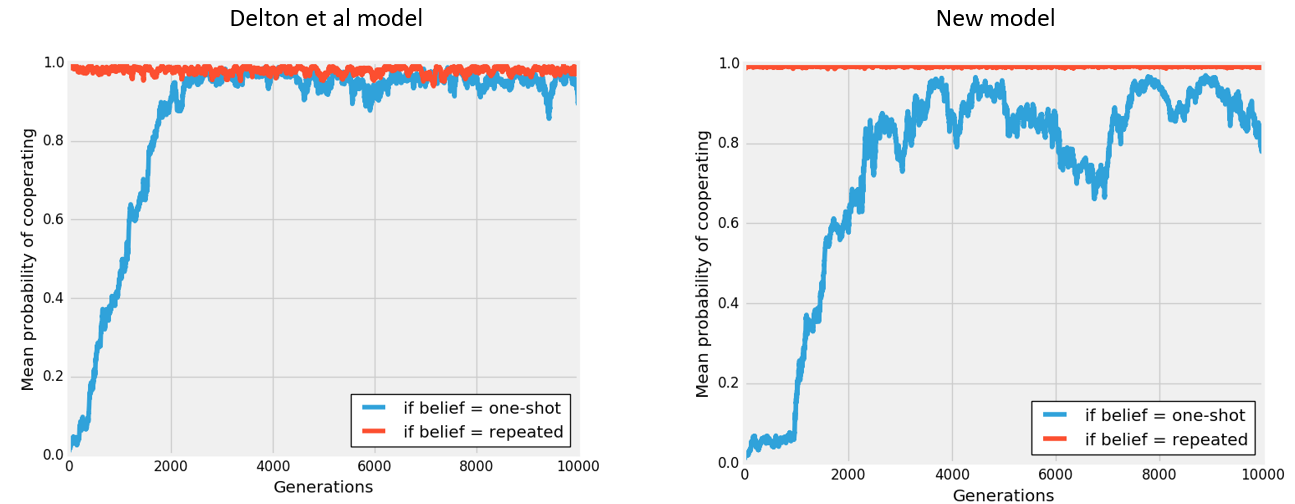
The figure below shows a typical run of the simulation for the two different versions of the model. For these two runs, the following parameters were used:
- The benefit of one's partner cooperating is 3 times the cost of one's own cooperation.
- On first meeting a new partner, the probability that the interaction will be repeated is 0.5
- If the first meeting is repeated, it is repeated an average of 20 times.
- The distance between the two distributions of possible cue values is 2 standard deviations.
The results vary depending on what values are chosen for the four parameters. The figure below shows the results of varying three of these four parameters. Rather than showing both of the heritable traits, these plots below show only the probability of cooperating when the agent believes the interaction is not to be repeated. Also, rather than showing how the average values of this inherited trait change across time, these plots below show only the average values of the trait at the end of each simulation (more specifically, the values are averaged across the final 500 generations of each simulation). For the results shown here, the distance between the two distributions of possible cue values was held constant at 2 standard deviations, while the values of the other three parameters were varied. For each of the 3x5x7 = 105 different combinations of parameter values, I ran the simulation 12 times and then calculated the average across those 12 simulations to ensure a reliable result.

Though the effect is slightly weaker in the revised model, the revised model generally supports the findings of Delton et al: depending on the chosen model parameters, the revised model still shows the plausibility of the evolution of a common tendency to cooperate even when an individual believes an interaction will not be repeated. I will soon publish these findings.
Run the simulation for yourself
I have created an interactive user interface for both versions of the simulation. In this app you can adjust various parameters of the model and then watch how the inherited traits evolve over time in the population. Download and run this R code in your R console:
shiny_app_evolution_of_cooperation.R
If you do not have R installed on your device, you can run the app remotely through your web browser using the link below. However, the app will run more smoothly if you run it on your own device using the R code provided above.
https://jamescragun.shinyapps.io/evolution_of_cooperation_under_uncertainty/